篇首语:本文由编程笔记#小编为大家整理,主要介绍了2023春招面试题:Redis数据库面试题整理相关的知识,希望对你有一定的参考价值。
Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能非关系型(NoSQL)的(key-value)键值对数据库。可以用作数据库、缓存、消息中间件等。
1)因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10 万次读写操作,是已知性能最快的 Key-Value 数据库。Redis 支持事务 、持久化
2)单线程操作,避免了频繁的上下文切换。
3)采用了非阻塞I/O 多路复用机制。I/O 多路复用就是只有单个线程,通过跟踪每个 I/O 流的状态,来管理多个 I/O 流。
1)String,字符串,是redis 的最基本的类型,一个 key 对应一个 value。是二进制安全的,最大能存储 512MB。
2)Hash,散列,是一个键值(key=>value)对集合。string 类型的 field 和 value 的映射表,特别适合用于存储对象。每个 hash 可以存储 232 -1 键值对(40 多亿)
3)List,列表,是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列边或者尾部(右边)。最多可存储232 - 1 元素(4294967295, 每个列表可存储 40 亿)
4)Set,集合,是string 类型的无序集合,最大的成员数为 232 -1(4294967295, 每个集合可存储 40 多亿个成员)。
5)Sorted set,有序集合,和set 一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。zset 的成员是唯一的,但分数(score)却可以重复。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
1.使用互斥锁(mutex key)业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间
2."永远不过期":这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
穿透:缓存不存在,数据库不存在,高并发,少量key
击穿:缓存不存在,数据库存在,高并发,少量key
雪崩:缓存不存在,数据库存在,高并发,大量key
Redis单节点存在单点故障问题,为了解决单点问题,一般都需要对redis配置从节点,然后使用哨兵来监听主节点的存活状态,如果主节点挂掉,从节点能继续提供缓存功能。主从配置结合哨兵模式能解决单点故障问题,提高redis可用性。从节点仅提供读操作,主节点提供写操作。对于读多写少的状况,可给主节点配置多个从节点,从而提高响应效率。
所以用哨兵解决以上问题。
Redis Sentinel(哨兵)主要功能包括主节点存活检测、主从运行情况检测、自动故障转移、主从切换。Redis Sentinel最小配置是一主一从。
Redis的Sentinel系统可以用来管理多个Redis服务器,该系统可以执行以下四个任务:
Redis 提供了不同级别的持久化方式:
IO模型使用了多路复用器,在linux系统中使用的是EPOLL
类似netty的BOSS,WORKER使用一个EventLoopGroup(threads=1)
单线程的Reactor模型,每次循环取socket中的命令然后逐一操作,可以保证socket中的指令是按顺序的,不保证不同的socket也就是客户端的命令的顺序性
命令操作在单线程中顺序操作,没有多线程的困扰不需要锁的复杂度,在操作数据上相对来说是原子性质的
自身的内存存储数据,读写操作不涉及磁盘IO
redis除了提供了Value具备类型还为每种类型实现了一些操作命令
实现了计算向数据移动,而非数据想计算移动,这样在IO的成本上有一定的优势
且在数据结构类型上,丰富了一些统计类属性,读写操作中,写操作会O(1)负载度更新length类属性,使得读操作也是O(1)的
如论选择哪种方法,最理想的情况下,两个操作要么同时成功,要么同时失败,否则就会出现Redis和数据库数据不一致的情况。
遗憾的是,目前没有什么框架能够保证Redis的数据和数据库的数据的完全一致性。我们只能根据场景和所需要付出的代码来采取一定的措施降低数据不一致出现的概率,在一致性和性能之间取得一个折中。
下面我们来讨论一下关于Redis和数据库之间数据一致性的一些方案。
当数据库数据发生变化的时候,Redis的数据也需要进行相应的操作,那么这个「操作」到底是用「更新」还是用「删除」呢?
「更新」的话调用Redis的set方法,新值替换旧值;「删除」直接删除原来的缓存,下次查询的时候重新读取数据库,然后再更新Redis。
结论:推荐直接使用「删除」操作。
因为使用「更新」操作的话,你会面临两种选择
第1种不用考虑了,下面讨论一下「先更新数据库,再更新缓存」这种方案。
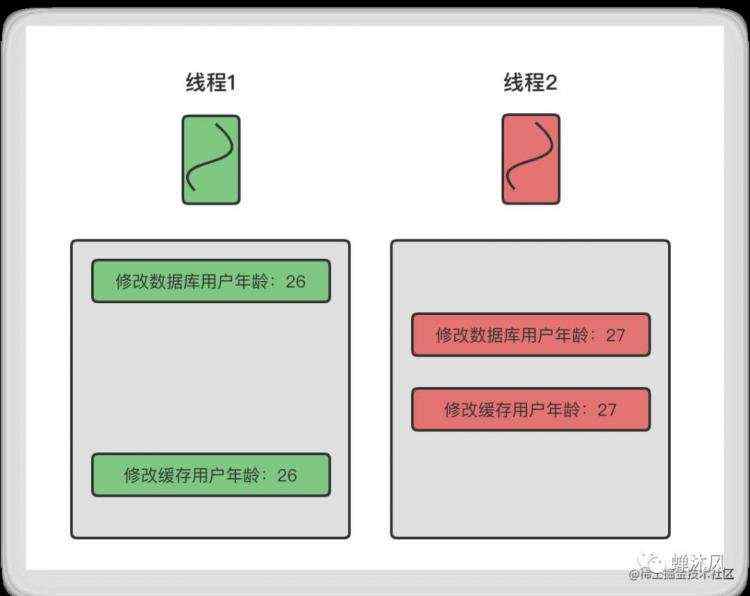
如果线程1和线程2同时进行更新操作,但是每个线程的执行顺序如上图所示,此时就会导致数据不一致,因此从这个角度上我们推荐直接使用删除缓存的方式。
此外,推荐使用「删除缓存」还有两点原因。
明确这个问题之后,摆在我们面前的就只有两个选择了:
这种方式可能存在以下两种异常情况
第2种情况应该怎么办呢?我们有两种方式:失败重试和异步更新。
如果删除缓存失败,我们可以捕获这个异常,把需要删除的 key 发送到消息队列。自己创建一个消费者消费,尝试再次删除这个 key,直到删除成功为止。

这种方式有个缺点,首先会对业务代码造成入侵,其次引入了消息队列,增加了系统的不确定性。
因为更新数据库时会往 binlog 中写入日志,所以我们可以启动一个监听 binlog变化的服务(比如使用阿里的 canal开源组件),然后在客户端完成删除 key 的操作。如果删除失败的话,再发送到消息队列。
总结
总之,对于删除缓存失败的情况,我们的做法是不断地重试删除操作,直到成功。无论是重试还是异步删除,都是最终一致性的思想。
这种方式可能存在以下两种异常情况

这时,Redis中存储的旧数据,数据库的值是新数据,导致数据不一致。这时我们可以采用延时双删的策略,即更新数据库数据之后,再删除一次缓存。

问题一:为何要延时500毫秒?
这是为了我们在第二次删除redis之前能完成数据库的更新操作。
假象一下,如果没有第三步操作时,有很大概率,在两次删除redis操作执行完毕之后,数据库的数据还没有更新,此时若有请求访问数据,便会出现我们一开始提到的那个问题。
问题二: 为何要两次删除redis?
如果我们没有第二次删除操作,此时有请求访问数据,有可能是访问的之前未做修改的redis数据,删除操作执行后,redis为空,有请求进来时,便会去访问数据库,此时数据库中的数据已是更新后的数据,保证了数据的一致性。
第一种策略:被动删除
当读一个key时,redis首先会检查这个key是否存在,如果存在且已过期,则直接删除这个key并返回nil给客户端。
第二种策略:定期删除
redis中有一系列的定期任务(serverCron),这些任务每隔一段时间就会运行一次,其中就包含清理过期key的任务,运行频率由配置文件中的hz参数来控制,取值范围1~500,默认是10,代表每秒运行10次。清理过程如下:
1.遍历所有的db
2.从db中设置了过期时间的key的集合中随机检查20个key
3.删除检查中发现的所有过期key
4.如果检查结果中25%以上的key已过期,则继续重复执行步骤2-3,否则继续遍历下一个db
调大hz将会提高redis定期任务的执行频率,如果你的redis中包含很多过期key的话,可以考虑将这个值调大,但要注意同时也会增加CPU的压力,redis作者建议这个值不要超过100。
如果redis使用的内存已经达到maxmemory配置的值时,会触发强制清理策略,清理策略由配置文件的maxmemory-policy参数来控制,有以下这些清理策略:
volatile-lru:使用LRU算法对设置了过期时间的key进行清理(默认值)
allkeys-lru:使用LRU算法对所有key进行清理
volatile-lfu:使用LFU算法对设置了过期时间的key进行清理(redis 4.0版本开始支持)
allkeys-lfu:使用LFU算法对所有key进行清理(redis 4.0版本开始支持)
volatile-random:对所有设置了过期时间的key进行随机清理
allkeys-random:从所有key进行随机清理
volatile-ttl:清理生存时间最小的一部分key
noeviction:不做任何清理,拒绝执行所有的写操作
为了节省内存和性能上的考虑,上述的清理策略都不需要遍历所有数据,而是采用随机采样的方法,每次随机取出特定数量(由maxmemory-samples配置项控制,默认是5个)的key,然后在这些key中执行LRU算法、RANDOM算法、或者是找出TTL时间最小的一个key,然后进行删除。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 